
嵌入式 Linux 进程间通信之管道通信:匿名与命名管道的奥秘
进程间通信与管道通信概述
进程间通信
进程间通信(Inter Process Communication,简称IPC)指的是进程之间的信息交换,进程间通信的方式有很多,比如管道通信、信号通信、共享内存、消息队列、信号量组、POSIX信号量等。
进程间通信可以达到数据传输、共享资源、控制进程等目的,方便用户对进程进行控制和管理。而管道通信是其中最基础、最易上手的一种。
管道通信
Linux中的管道通信,核心特点是半双工通信,同一时刻只能“发送数据”或“接收数据”中的一个操作,无法双向同步同时通信。就像现实中的水管,水只能从一端流向另一端,不能双向对流。
设计理念非常简单:模拟现实中的“管道”,让数据从一端写入、另一端读出,实现进程间的单向数据传递,适合简单的场景下的数据交互。
管道在Linux系统中属于“文件”的一种,但它又不是普通文件,而是一种“特殊文件”。它支持和普通文件一样的read()/write()操作,但不支持lseek()(无法指定位置读写),数据写入管道后会暂存在内核缓冲区,读取后就会从缓冲区中删除,不会持久化存储。
Linux系统中的管道文件分为两种:匿名管道(pipe)、命名管道(fifo)。
匿名管道(pipe):亲缘进程的“秘密通道”
匿名管道,顾名思义,没有文件名,这是它最核心的特征,也决定了它的使用局限性:
- 无文件名,无法通过open()函数创建和打开,只能通过专门的系统调用创建。
- 仅适用于有亲缘关系的进程(最常用的是父子进程),无法用于无亲缘关系的进程间通信。
- 数据读写方式和普通文件一致,支持read()/write()操作。
- 不保证数据的原子性,多进程同时写入时可能出现数据错乱。
问题:匿名管道无文件名,如何创建和访问?
Linux系统提供pipe()系统调用,专门用于创建匿名管道;创建成功后,会返回两个文件描述符,
分别对应管道的“读取端”和“写入端”,进程通过这两个文件描述符就能访问管道。
pipe()函数创建匿名管道
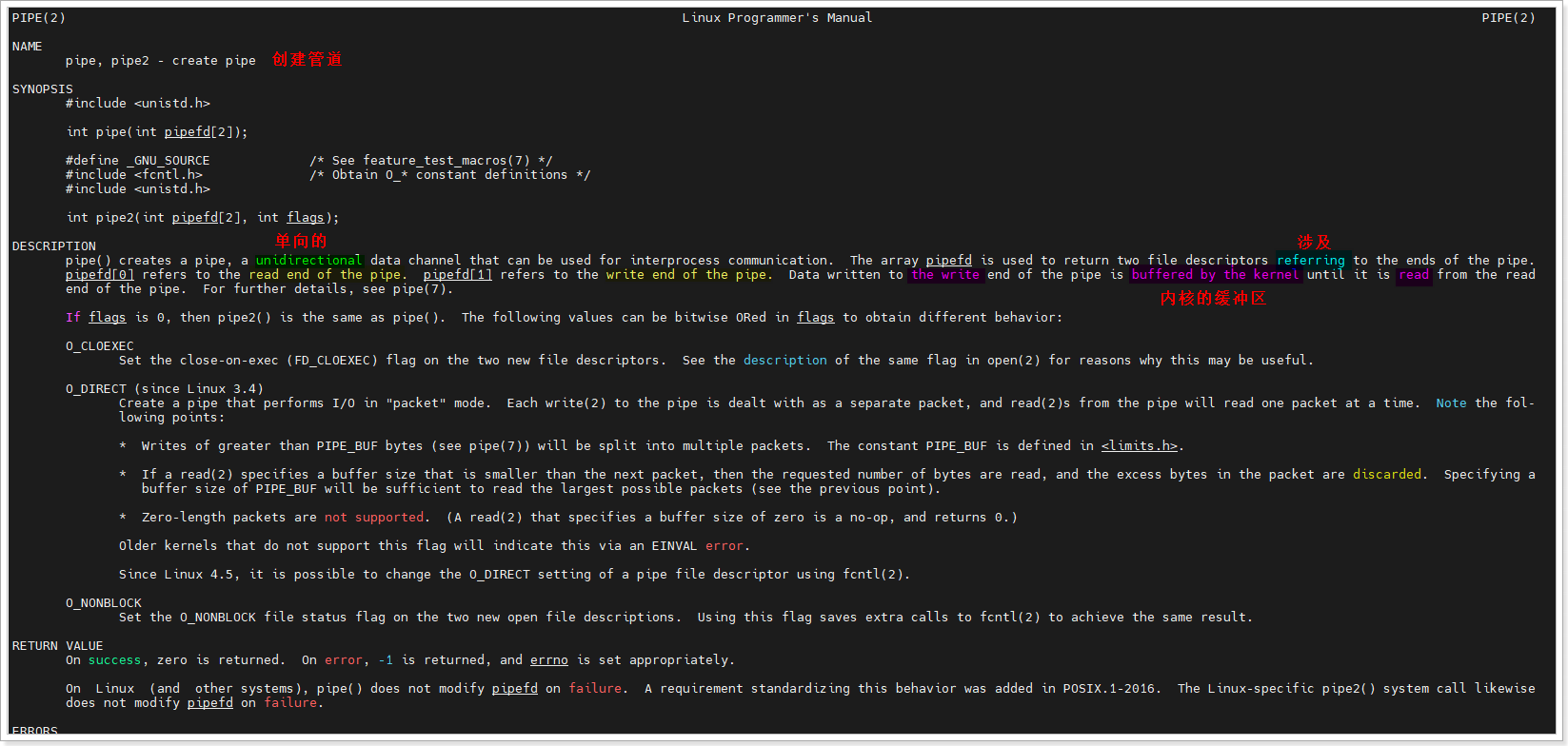
pipe()函数只有一个参数 int pipefd[2],这是一个长度为2的数组,专门用于存储管道的两个文件描述符:
pipefd[0]:对应管道的读取端,只能用于read()操作,无法写入。pipefd[1]:对应管道的写入端,只能用于write()操作,无法读取。
用户把对数据写入到管道之后,数据是会在内核的缓冲区中进行暂存的,直到从管道中读取该数据为止。
匿名管道的核心工作机制
-
内存暂存:进程向管道写入数据后,数据不会直接传递给进程接收,而是先暂存在内核缓冲区,知道接收进程调用read()读取数据,数据才会从缓冲区移除
-
缓冲区大小:Linux系统中,管道的内核缓冲区默认大小是4M,可以使用
ulimit -a查看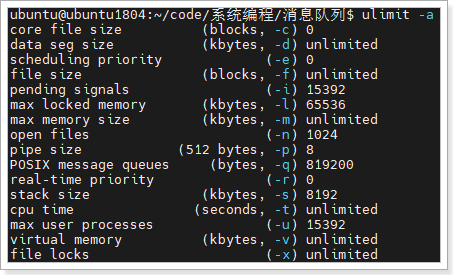
-
阻塞特性:
- 写入阻塞:如果写入速度快于读取速度,内核缓冲区会被写满,此时继续调用write()写入数据,进程会被阻塞(挂起),直到缓冲区有空闲空间。
- 读取阻塞:如果读取速度快于写入速度,管道内(缓冲区)没有数据时,继续调用read()读取数据,进程会被阻塞(挂起),直到有新的数据写入管道。
-
阻塞的意义:阻塞状态会让当前进程挂起,释放CPU资源,让其他需要CPU的进程高效利用资源,从而提高整个系统的吞吐量,这是Linux系统资源调度的重要优化。
问题:匿名管道适用于什么场景?什么时候创建最合适?
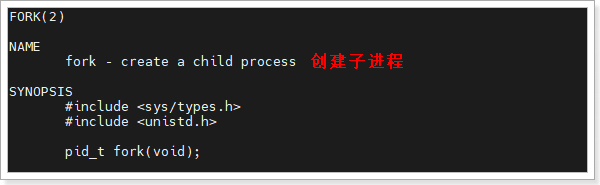
由于管道没有文件名,所以仅适合有亲缘关系的进程(父子、兄弟),因为这类进程可共享文件描述符,无需通过文件定位管道。
必须在创建子进程(fork())之前创建匿名管道。因为fork()创建子进程时,会复制父进程的代码段、数据段、堆栈段,以及所有打开的文件描述符——如果父进程先创建管道,子进程会自动复制管道的两个文件描述符,这样父子进程就能通过这两个文件描述符访问同一个管道;如果先fork()再创建管道,子进程不会拥有管道的文件描述符,无法访问管道。
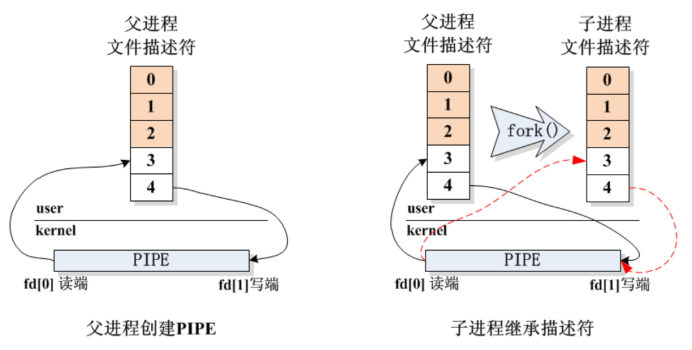
匿名管道不保证数据的原子性
匿名管道更适合“一对一”的亲缘进程通信,不适合多进程同时写入的场景。
命名管道(fifo):无亲缘关系进程的“公共通道”
匿名管道的局限性很明显:只能用于亲缘进程、一对一通信。为了解决这个问题,Linux系统提供了命名管道(Named Pipe),也叫有名管道、具名管道(简称fifo),它弥补了匿名管道的不足,支持无亲缘关系的进程间通信。
命名管道和匿名管道的核心区别,就是有自己的文件名,这个特点也决定了它的优势:
- 有文件名,属于Linux系统中的“管道文件”(可通过ls -l查看,文件类型标识为p)。
- 支持open()函数打开,读写方式和普通文件一致(read()/write()),但不支持lseek()(无法指定位置读写)。
- 适用场景:无亲缘关系的进程间通信(比如两个完全独立的程序),也支持有亲缘关系的进程。
- 支持多路同时写入:多个进程可以同时向同一个命名管道写入数据,且能保证数据的原子性(写入数据量不超过PIPE_BUF时)。
问题:怎么保证数据原子性
从原理上来说,内核为命名管道维护了一个缓冲区。当进程进行写入操作时,内核会先将数据暂存到这个缓冲区中。如果写入的数据量小于等于 PIPE_BUF,内核会保证这整个写入操作是原子性的。这是因为在这种情况下,内核可以将该写入操作作为一个整体来处理,在这个操作完成之前,不会被其他进程的写入操作打断。
如果写入的数据量超过了 PIPE_BUF,内核就无法保证原子性了。因为此时数据量较大,内核可能会将其拆分成多个部分来处理,这样就可能出现其他进程在这个大写入操作中间插入自己的写入,导致数据混乱。
mkfifo()函数创建命名管道
访问命名管道的前提是:命名管道已经存在。Linux系统提供了mkfifo()函数,专门用于创建命名管道。
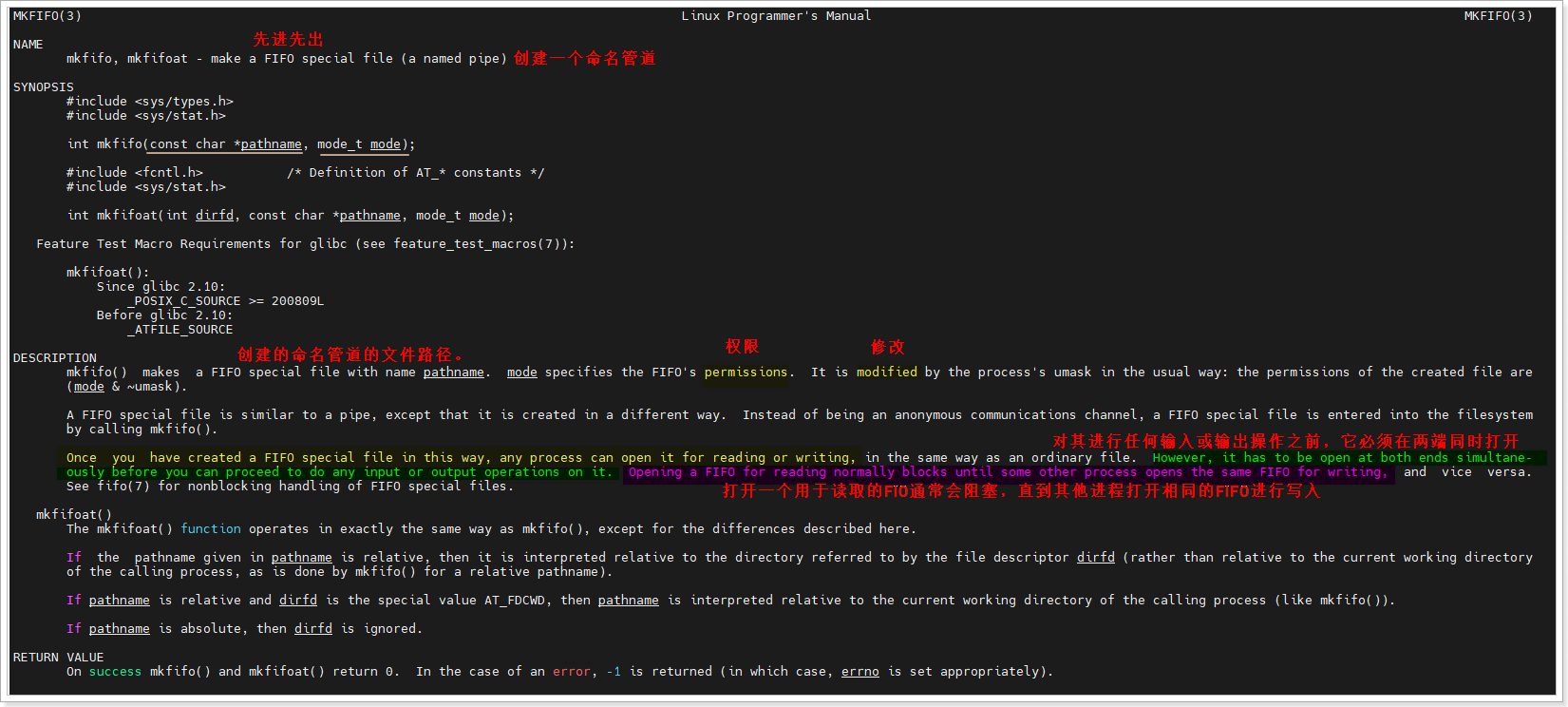
const char *pathname:命名管道的文件路径和名称(如"/tmp/myfifo")。- 重点注意:创建命名管道时,路径必须位于Linux系统内部(比如虚拟机中的Linux目录),不能创建在Windows共享文件夹中—— 因为共享文件夹属于Windows系统路径,Linux的管道机制无法在Windows路径下生效,会导致创建失败。
mode_t mode:命名管道的访问权限,和open()函数的mode参数一致,采用八进制表示,分为三类权限(所有者、所属组、其他用户)。- 常用权限:0644(所有者可读可写,其他用户只读)、0666(所有用户可读可写)—— 管道无需执行权限,因此权限的最后一位(执行权限)设为0即可。
总结
- 管道通信的核心是“半双工”,数据单向流动,暂存在内核缓冲区(默认4M),无持久化
- 匿名管道:无文件名,依赖亲缘进程,fork()前创建,适合简单的父子进程通信
- 命名管道:有命管道,支持无亲缘进程通信,需用mkfifo()创建,支持多进程安全写入
- 重点函数:pipe()/pipe2()(匿名管道)、mkfifo()(命名管道),以及read()/write()的使用。