
Shell
Shell脚本实现命令自动化执行
基本规范
文件名:.sh后缀,创建touch test.sh
首行必备:#!bin/bash指定解释器
注释:#
输入:read
输出:echo
赋值时,等号两边无空格
buf="hello world"
运行:source命令
通配符
|
|
管道
有两种不同的执行模式
cmd1 | cmd2
指将cmd1的输出作为cmd2的输入,比如:
|
|
cmd1 |xargs cmd2
将cmd1的输出作为cmd2的参数
|
|
重定向
> 输出重定向 覆盖
< 输入重定向
>> 追加
|
|

反引号
在shell脚本中,经常使用的一个特殊符号,反引号 ` ,放在反引号的命令会被解释器执行,反引号可以在双引号"“中进行嵌套

数值运算
脚本的变量类型默认都是字符串,对变量进行数值运算时,可以使用双括号实现
|
|
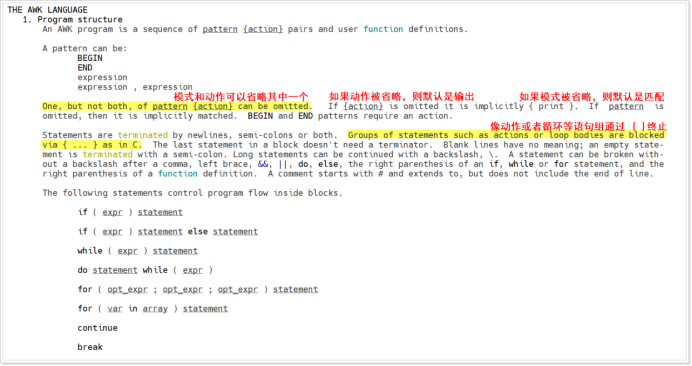
脚本控制语句
if语句:单分支、双分支、多分支
|
|
表达式写在[ ]中,并且[ ]中的表达式两边必须有空格
判断语句结束是以if的逆序书写fi作为结束标志
对于[ ] 而言,其实是shell脚本中的test命令的另一种形式,在man手册中有相关描述
|
|
|
|
[ ]中的表达式也可以使用逻辑运算符进行逻辑运算,shell支持逻辑与&&、逻辑或||、逻辑非!,规则和C语言一致。注意:逻辑运算符和表达式中间要有空格
case语句:
|
|
循环语句
while:
|
|
|
|
for:
|
|
until:
|
|
until 循环的规则是如果条件成立,则立即退出循环。否则一直进行循环。
break跳出循环,或者使用continue结束一次循环
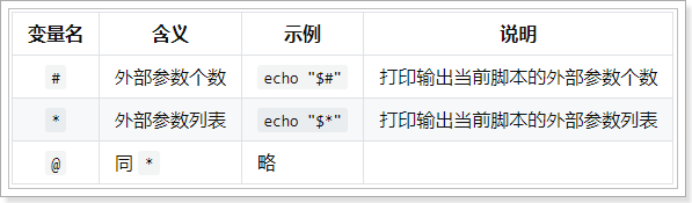
shell脚本外部传参
|
|
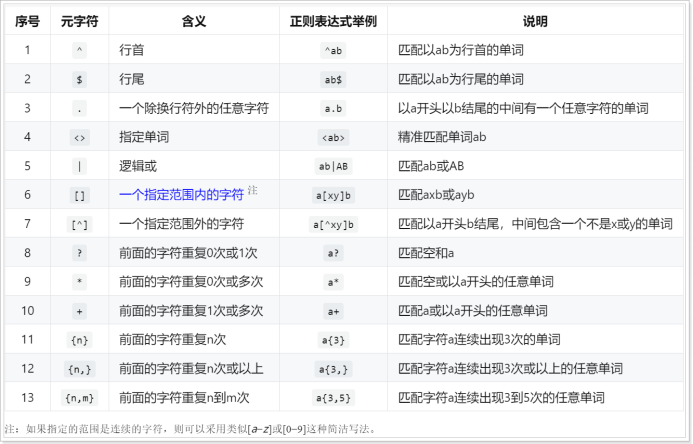
shell正则表达式
正则表达式(Regular Expression,通常简称RE)指的是使用一些具有特定含义的字符,去组合成具有某种特定规律的字串。然后利用这些特定的字串,去对文本、选项、参数等进行比对、抽取等动作,可以提高开发效率。
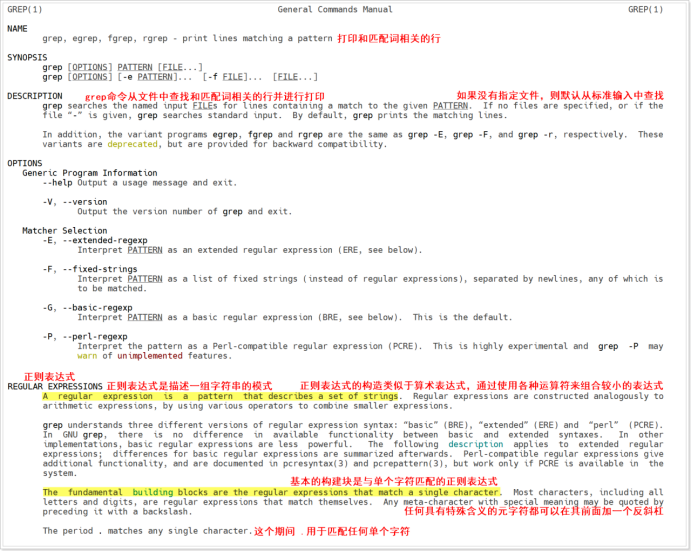
常用的过滤器有grep、awk、sed
grep
用于指定文件或目录中查找某些字符串

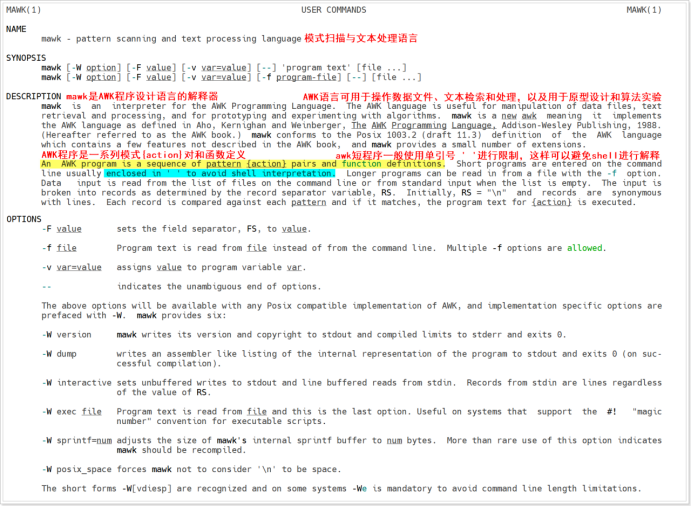
awk
一种用于处理文本的编程语言工具,它以行为单位,每次读取文件中的一行,查找与命令行中所给定内容相匹配的模式,如果发现匹配内容,则进行下一个过滤步骤。如果找不到匹配内容,则继续处理下一行。
|
|
例子:当前一个名称叫做grade.txt的文本中处理使用awk进行查找和分析,使用规则如下:
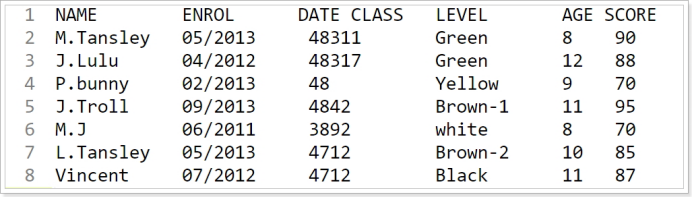
-
显示指定列
1awk '{ print $1, $5 }' grade.txt$1表示第1列,2表示第2列,n表示第n列,而$0表示整一行(也就是所有列)。
-
格式化输出
1awk '$5==11 && $6>=90 { print $0 }' grade.txt -
过滤
1awk '$5==11 && $6>=90 { print $0 }' grade.txt读取grade.txt的一行信息,判断第五列(即$5)是否等于11而且第6列(即$6)是否大于等于90,如果是,则显示整一行(即print $0)。然后读取下一行。
-
显示表头
1awk 'NR==1 || $6>=90 { print }' grade.txtNR表示已经读出的记录数(即行号),另外print后面什么都没跟,所以等价于print $0
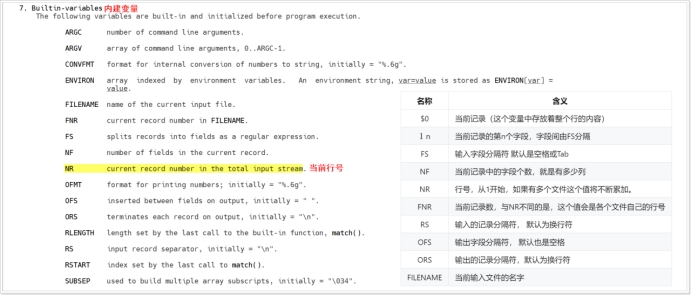
AWK语言提供了一些内建变量,这些内建变量在程序执行前就已经提前建好并被初始化好。
-
指定分隔符
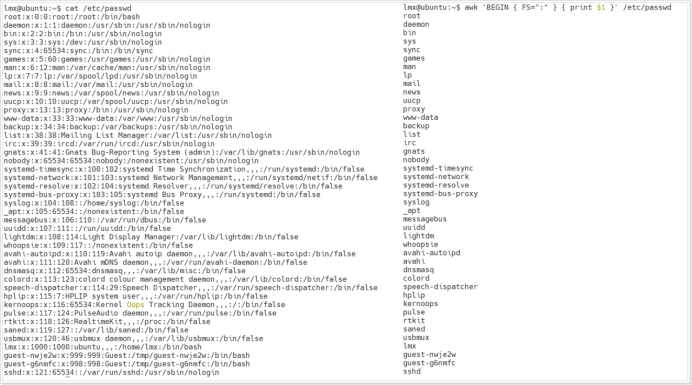
1awk 'BEGIN { FS=":" } { print $1 }' /etc/passwd上面这句话的意思是:把/etc/passwd文件中冒号:之前的那一列进行输出,BEGIN意味着紧跟在它后面的动作 {FS=”:"} 会在 awk 读取第一行之前处理。
-
匹配字符串
1awk ' $0~/Brown/ {print} ' grade.txt上面这句话的意思是:将文档中所有匹配Brown的行显示出来。其中$0~/Brown/ 是一个条件,表示所指定的域(这里是$0)要匹配的规则(这里是Brown),也就是grade.txt中的一行只要包含有单词Brown,就会被选出来然后显示出来。
-
信息重定向
1awk ' {print > $5} ' grade.txt上面这句话的意思是:每一行都将被重定向到以第5个域(年龄)命名的文件中去。也可以将指定的域重定位到相应的文件。
sed
sed指的是stream editor流编辑器,sed 的工作就是把文件或字符串里面的文字经过一系列编辑命令转换为另一种格式输出。跟 awk 过滤器类似,sed也是一次读取文件的一行信息加以处理,然后再读取下一行,以此类推。

-
进行替换
1sed "s/-year/ years/" people.txt意思是从people.txt中读取一行,然后使用正则表达式-year来试图匹配某单词,如果匹配成功,则将之替换成” years”。
-
指定替换
1sed "2s/-year/years/" people.txt意思是将第2行的"-year"改成" years"。 如果想修改其中几行,则可以写成”2,5s/year/years”
-
修改原文
1sed -i "2s/-year/years/" people.txt需要注意:默认情况下sed不会修改原文,默认状态下sed只是对原文的复制品进行了加工。
-
插入信息
1 2 3 4 5 6 7sed '3i x' people.txt 在第3行的前面插入x sed '2a x' people.txt 在第2行的后面插入x sed '1,4a x' people.txt 分别在第1至4行后插入x sed '/US/a x' people.txt 在匹配US的行后插入x -
指定删除
1 2 3sed '2d' people.txt 将第2行给删掉 sed '/US/d' people.txt 将匹配/US/的所有行删掉 -
匹配显示
1 2 3 4 5 6 7gec@ubuntu:~$ sed '/Chen/p' people.txt -n 显示匹配Chen的行 gec@ubuntu:~$ sed '/Chen/, /Lau/p' people.txt -n 显示匹配Chen或者Lau的行 gec@ubuntu:~$ sed '3,/UK/p' people.txt -n 从第3行开始显示直到匹配UK为止 gec@ubuntu:~$ sed '/UK/,6p' people.txt -n 从匹配UK的行开始显示直到第6行为止